
Lecture 2 KNN
학교 수업 복습 칸입니다. 26년 Machine-Learning
들어가면서.
지난학기 수업을 좀 복습해야 하는데 하다가 시간을 넘겨버렸다. 그래서 깔끔하게 포기하고, 이번학기 수업의 내용을 간단히 복습해보려 한다.
KNN
여러개의 데이터가 주어졌다.
그리고 주어진 데이터 이외의 점들을 놓고 이 점이 어느 분류에 속하는지 알아보고 싶을때 가장 쉽게 생각할 수 있는 알고리즘이 KNN알고리즘이다.
그래서 이 알고리즘의 두개의 키워드를 꼽으라면, “분류(Classification)” 과 “회귀(Regression)”이 된다.
K 개의 이웃을 보라.
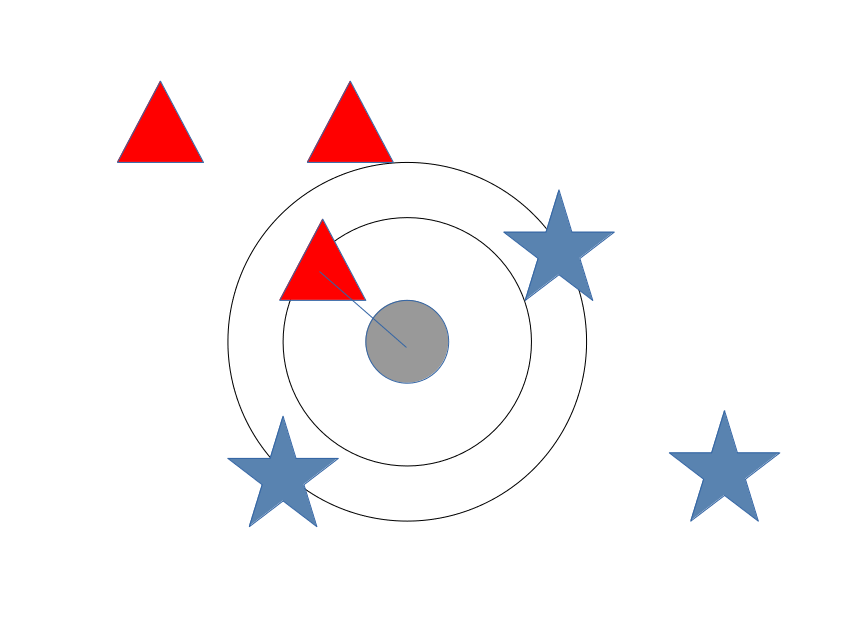
중앙의 회색 원을 무슨 색으로 칠해야 할까. 이웃과 같은 색으로 칠하고자 한다.
-
가장 가까운 이웃 한개만 본다면 (k=1) 빨간색으로 칠해야 한다.
-
가장 가까운 이웃 세개를 보면 (k=3) 파란색이 되어야 한다.
-
가장 가까운 이웃 6개를 보면 (k=6) 다시 빨간색이 되어야 한다.
이렇듯 KNN 은 몇개의 이웃값을 보고, 현재 추정하고자 하는 포인트의 값을 찾아내는 과정이다.
따라서 수식으로 표현해보면,
\[d(\mathbf{x}, \mathbf{x}_i)=\|\mathbf{x}-\mathbf{x}_i\|_2\] \[d(\mathbf{x}, \mathbf{x}_i) = \sqrt{\sum_{j=1}^{d}(x_j-x_{ij})^2}\]이것과 같다.
Code review
KNN 의 성능을 보기 위해 MNIST 데이터셋을 이용해 분류 문제를 한번 풀어보자.
전체 코드는 다음과 같다.
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import numpy as np
# 1. MNIST 불러오기
mnist = fetch_openml('mnist_784', version=1, as_frame=False)
X = mnist.data # (70000, 784)
y = mnist.target.astype(np.int64)
# 2. 픽셀값 정규화
X = X / 255.0
# 3. train / test 분리
# 원래 MNIST는 60000 / 10000으로 나누는 경우가 많지만
# 여기서는 간단히 train_test_split 사용
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=10000, random_state=42, stratify=y
)
# 4. kNN 모델 생성
# n_neighbors=k : 가까운 이웃 몇 개를 볼지
knn = KNeighborsClassifier(n_neighbors=3)
# 5. 학습
knn.fit(X_train, y_train)
# 6. 예측
y_pred = knn.predict(X_test)
# 7. 성능 평가
acc = accuracy_score(y_test, y_pred)
print("Accuracy:", acc)
가볍게 복/붙해서 결과를 보면 굉장히 높은 정확도를 가진다는걸 알수 있다. 실행 결과를 시각화해보면 이렇다.
import matplotlib.pyplot as plt
# 테스트 샘플 5개 선택
num_samples = 5
plt.figure(figsize=(10,3))
for i in range(num_samples):
img = X_test[i].reshape(28,28)
true_label = y_test[i]
pred_label = y_pred[i]
plt.subplot(1, num_samples, i+1)
plt.imshow(img, cmap='gray')
plt.title(f"T:{true_label} P:{pred_label}")
plt.axis('off')
plt.show()

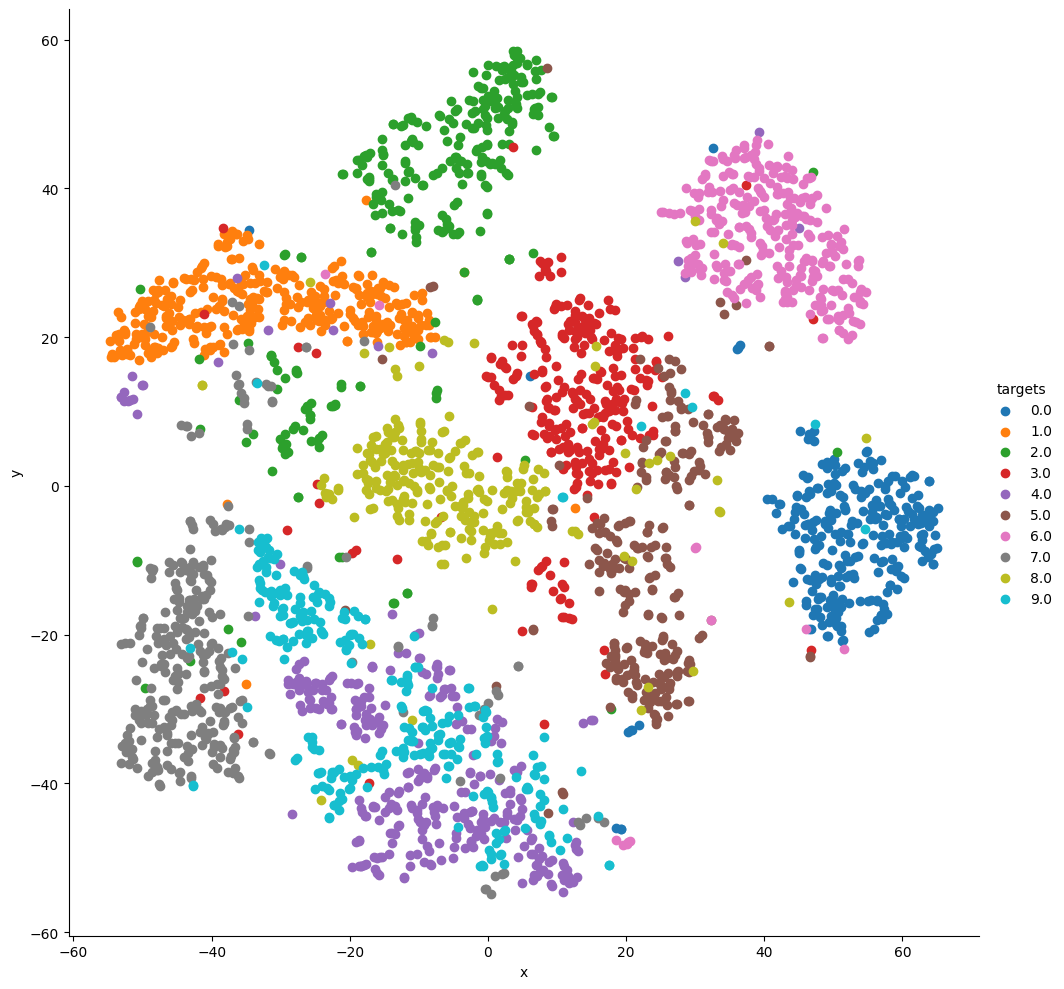
데이터셋의 Embedding Space를 보면 다음과 같다. 이 Plot에서 입력 이미지가 어느 쪽에 가까운가를 알게 되면 그 이미지가 어느 숫자에 해당하는지 알 수 있는것이다.
왜 쓸까.
KNN은 학습이 거의 필요없다. 그래서 데이터를 저장하고, 입력 샘플 x 가 들어오면, 각 데이터들과의 거리를 계산해서 가장 가까운 k 개를 선택하고 다수결로 결정한다. sklearn에서 추가로 이루어지는건 인덱싱과 탐색에 대한 알고리즘이 붙은 것일 뿐이다. 따라서 학습이란 과정이 크게 필요하진 않다.
만약 시스템이 단순하거나, 데이터가 많지 않을 경우, 굳이 학습에 얽매이기보다는 간단한 KNN 알고리즘도 나름 효율적인 시스템이 될 수 있다.
KNN_scratch
알고리즘의 핵심부분만 함수로 만들어보면 다음과 같다.
from collections import Counter
def knn_predict_one(x, X_train, y_train, k=3):
# 각 학습 샘플과의 거리 계산
distances = np.linalg.norm(X_train - x, axis=1)
# 가까운 k개 인덱스
knn_idx = np.argsort(distances)[:k]
# 다수결
knn_labels = y_train[knn_idx]
pred = Counter(knn_labels).most_common(1)[0][0]
#빈도수 구하고, 가장 높은 빈도수의 class 를 출력한다.
return pred
# 테스트
correct = 0
for i in range(len(X_test)):
pred = knn_predict_one(X_test[i], X_train, y_train, k=3)
if pred == y_test[i]:
correct += 1
print("Accuracy:", correct / len(X_test))
댓글남기기