
Particle Filter, Fast SLAM
시작하면서.
Particle Filter 는 고전 SLAM에서 가장 많이 썼던 SLAM의 쌍벽 중 하나다. 보통 고전 SLAM이라 하면 Filter 기반 SLAM이라고도 하는데, 하나는 Kalman Filter 기반의 SLAM이라면, 다른 하나가 Particle Filter 가 되시겠다.
Kalman Filter 는 Covariance(공분산)을 이용한 선형식에 기반하여 관측값, 자기 위치를 업데이트한다고 요약한다면, Particle Filter는 측정된 관측값들과 Monte-Carlo 기법을 이용하여 자신의 위치를 업데이트하는 전략을 취한다. 이 특성으로 인해 비선형적인 시스템에서 강력한것이 이 Particle filter다.
그래서 이론만 가지고 연구할땐 Kalman filter나 Particle Filter 둘 중 하나만 사용하는 경우가 많지만, 실무의 영역에선 두 필터를 경우에 따라 적절하게 섞어서 사용하는 경우가 많았다. 예를 들어 Local Map의 업데이트는 KF(Kalman Filter) 기반이라면, Global Map에서 로봇의 위치를 찾는데는 PF(Particle Filter)를 사용한다던가 하는 방식이다.
또 하나는 LiDAR 와의 궁합이 좋아서, LiDAR를 사용하는 로봇청소기 중 초창기 버전은 PF를 많이 사용했던 것으로 알고 있다. 물론 LiDAR에서도 KF 를 적용하여 사용할 수도 있다. 하지만, Global Map에서 자기위치를 찾을 수 있는 방법을 논할때, BoW(Bag of Words) 의 사용이 가능한 Vision SLAM에 대비해 2D-LiDAR은 이렇다 할 방법이 없었는데 이때 PF 기반의 알고리즘들이 강력한 대안이 되어준다.
지금은 Neural Network 기반의 알고리즘들도 종종 등장한다.
하지만, 제어 분야에 오래된 격언이 있다.
가장 기초적인 것도 되지 않는게 고급기능 넣는다고 그 성능이 드라마틱하게 바뀌지 않는다.
PID 로 되지 않는 놈이 SMC 넣는다고 제어가 되는게 아니다. (하는 사람도 있지만, 그건 천재의 영역이고)
PF조차 안되는놈이 NN쓴다고 갑자기 되는 경우는 없다..(고 믿고싶다.)
논문 읽어보기
이제 고전을 하나 읽어보자. PF 가 유명해지기 시작한 그 첫번째 논문. 1999년 ICRA에서의 일이다.
F. Dellaert, D. Fox, W. Burgard and S. Thrun, “Monte Carlo localization for mobile robots,” Proceedings 1999 IEEE International Conference on Robotics and Automation (Cat. No.99CH36288C), Detroit, MI, USA, 1999, pp. 1322-1328 vol.2, doi: 10.1109/ROBOT.1999.772544.
https://ieeexplore.ieee.org/document/772544
또는
https://publications.ri.cmu.edu/storage/publications/pub_files/pub1/dellaert_frank_1999_2/dellaert_frank_1999_2.pdf

저자 하나하나 모두가 유명하고 레전드들이다. (SLAM분야에 있어서.)




Sebastian Thrun, Wolfram Burgard, Dieter Fox 이 셋은 SLAM 학도들의 영원한 바이블 격인 Probabilistic Robotics 의 저자이다. 2010년대까지만 하더라도 로봇 전공한다고 하면 이 책을 한번쯤은 거쳐가야 했고, 로봇공학 전공하고 졸업했습니다 하는 사람의 책상에 꼭 한권씩은 끼워져있던 책이었다.(심지어 기계설계담당자 책상에도 꽂혀있더라.)

이제는 시절이 좋아져서, 번역본도 등장했다. …….. 정말 좋은 시절이다.
나땐 저거 배우다 영어의 문턱에서 좌절했었는ㄷ……..

어쨋건 교재와 논문 둘다 한번쯤은 읽어보길 권장한다.
여기선 상세히 다룬다기보단, 이런 순서로 PF 가 흘러간다 하는 맥락을 설명해보고자 한다.
논문의 Introduction을 읽어내려가다보면, 이 논문의 핵심을 짚는 단어가 나온다.
In this paper we present the Monte Carlo Localization method (which we will denote as the MCL-method) where we take a different approach to representing uncertainty: instead of describing the probability density function itself, we represent it by maintaining a set of samples that are ran- domly drawn from it. To update this density representation over time, we make use of Monte Carlo methods that were invented in the seventies, and recently rediscovered in- dependently in the target-tracking, statistical and computer vision literature
몬테카를로 기법을 이용해서 샘플링을 하고, 업데이트한다가 핵심이다.
- In contrast to Kalman filtering based techniques, it is able to represent multi-modal distributions and thus can globally localize a robot.
칼만 필터 방법 대비, 전역 위치 찾기에 장점이 많다는 이야기이다. 실제로 이런 특성 때문에 많이 쓰인다.
- It drastically reduces the amount of memory required compared to grid-based Markov localization, and it can integrate measurements at a considerably higher frequency.
칼만필터스타일은 관측 데이터를 행렬로 표기하기때문에 맵의 크기가 커지면 커질수록 핸들링해야 하는 행렬의 크기가 커진다. 그러다 메모리가 폭주하는데.. 사실 이건 옛날 마이컴에서 SLAM하던 시절 이야기고, 지금은 많이 좋아져서 어떻게든 연산이야 해내겠다마는, PF 방식의 SLAM이 메모리를 덜 차지한다는건 어쩔수 없는 사실이다. 샘플링하는 포인트 개수만큼의 메모리만 있으면 되기 때문에, 맵이 커지면 커질수록 유리해진다.
- It is more accurate than Markov localization with a fixed cell size, as the state represented in the samples is not discretized.
뭐…. 정확도는 잘 모르겠다…………. 다만 대부분의 SLAM Map들이 Grid Map의 형태를 띄고 있으므로 Int형으로 정의하고 연산하기 좋은 PF가 여러모로 편리한 방법일거다.
- It is easy to implement.
근데, 이건 정말 그렇긴 하다.
논문에서의 수학들.
잘 다루고 싶진 않지만(내가 실력이 부족하다.)
이 논문에서 반드시 알아야 할 수학적인 개념들은 한번 짚고 넘어가야 한다.
1. Predictive density
로봇이 센서를 통해 거리값들을 관측했다고 생각해보자. 그리고 그 값을 통해, “여기가 어디지?” 라는 질문을 할 수 있다.
다른 비유를 해보자.
지금 당신은 등산을 하고 있…..아니, 낙하산을 타고 있다가 태백산맥 어딘가즈음에 떨어졌다.
당신에게 주어진건 나침반 하나와 지도 하나. 이제 내가 어디있는지를 찾아야 한다.
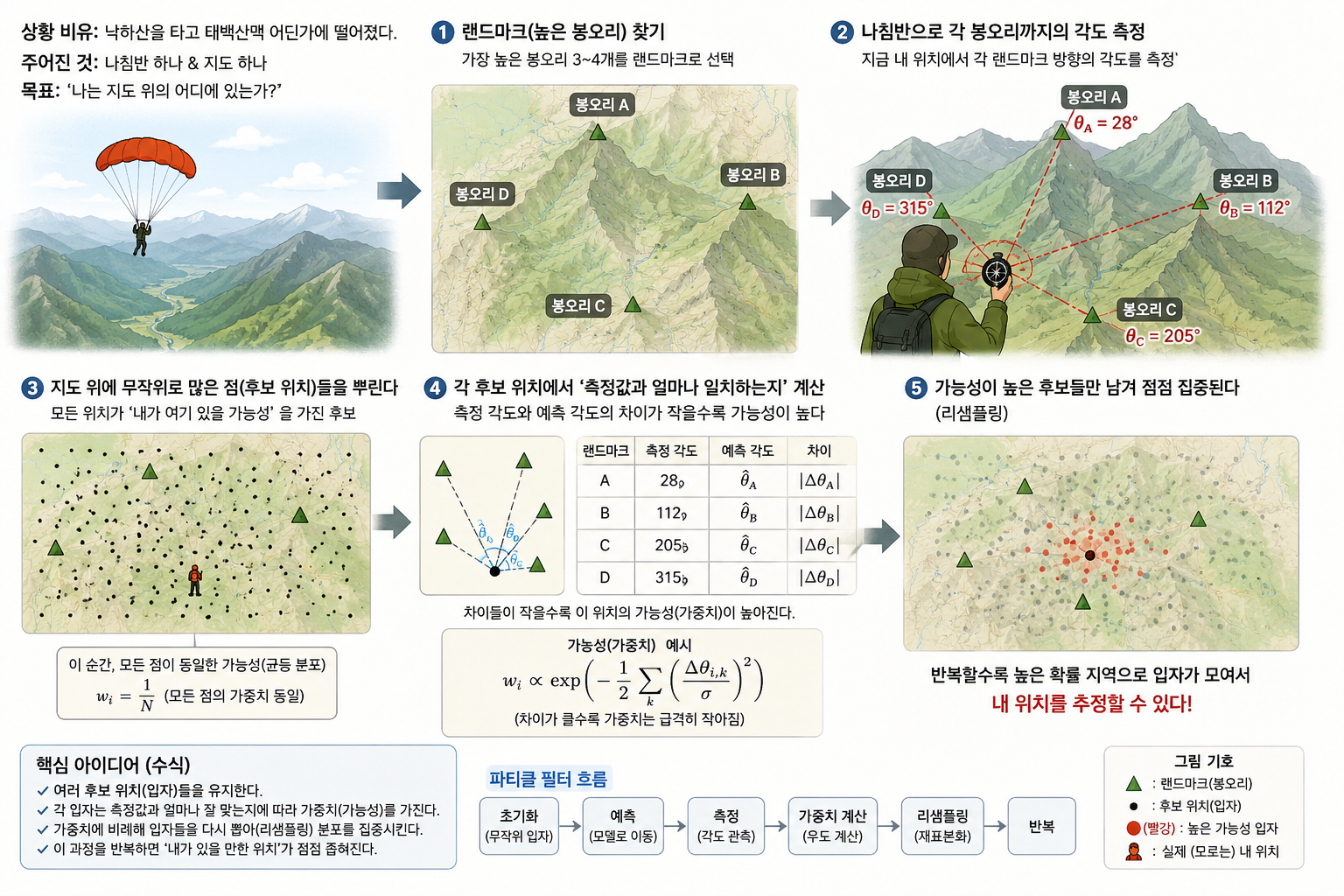
제일먼저 하는건 랜드마크를 찾아야 한다. 가장 높은 봉오리 3~4개정도를 찾아본다. 그리고 나침반을 이용해 지금 내 위치에서 각 봉오리들까지의 각도값을 측정해냈다. 이 지점에서 봉오리 세개가 그렇게 보일 확율은 얼마일까? 지도 전체에서 무작위로 점을 찍어가다가, 점점 가능성이 높은 후보지를 찾아낼 수 있을 것이다. 그 가능성을 우선 수식으로 표현하면 이렇다는 것이다.
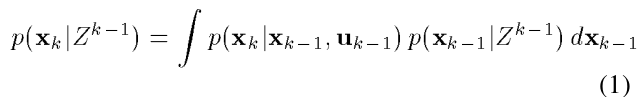
X가 뭐고, Z가 뭐고 크게 언급하진 않지만, 앞으로 SLAM 논문에서 X는 로봇의 상태(state vector, x,y,각도같은 위치관련값), Z는 관측값(Measurement,거리와 각도 등), u는 제어입력(속도. 속도.. 음.)이라고만 알고 있자.
저 식은 적분식이란건데, 지금 로봇이 가지고 있는 관측값들을 비추어 보았을때, 지도의 어떤 포인트가 될 가능성들을 모두 더한다고만 생각하자. 앞서 논문에서 메모리를 많이 안먹는다고 하지만 이 적분식으로 인해 만약 관측값이 무진장하게 많아질 경우 연산량이 증가하는 원인이 된다. (정확하게는 되었었다. 마이컴 시절.)
2. Update phase
어쨌거나 지도상에서 후보지가 서너군데즈음 있다고 가정한다. 여기서 나는 산을 내려가야 하니까, 우선 남쪽으로 이동한다고 가정해보자. 대략 1시간쯤 걸어내려갔고, 나의 이동속도를 감안했을때 얼마만큼 움직였더니, 어라? 좀전에 봤던 봉우리의 각도가 바뀌었다.
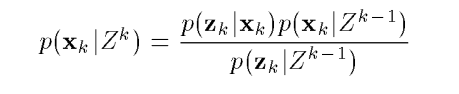
이제 좀전의 후보 포인트들에서, 내가 움직인 값을 반영했을때 확율을 다시 계산할 수 있다. 이 업데이트를 통해 확율이 떨어지는 후보는 제외해나가면서, 내가 있는 정확한 위치를 찾아갈 수 있다.
이게 Particle Filter의 기본 개념이다.
- 내 관측값들을 이용해서 지금 어디있는지 후보지역을 찾고.
- 조금 이동했을때의 관측값의 변화를 가지고 후보지역별 확율을 업데이트해서,
- 후보가 아닌것들을 제거하는 과정을 반복한다.
여기에 좀 더 테크닉들이 들어가면 가중치라는 개념이 들어가고, 다시 샘플링하고, 계산하고 하는 작업들이 반복된다.
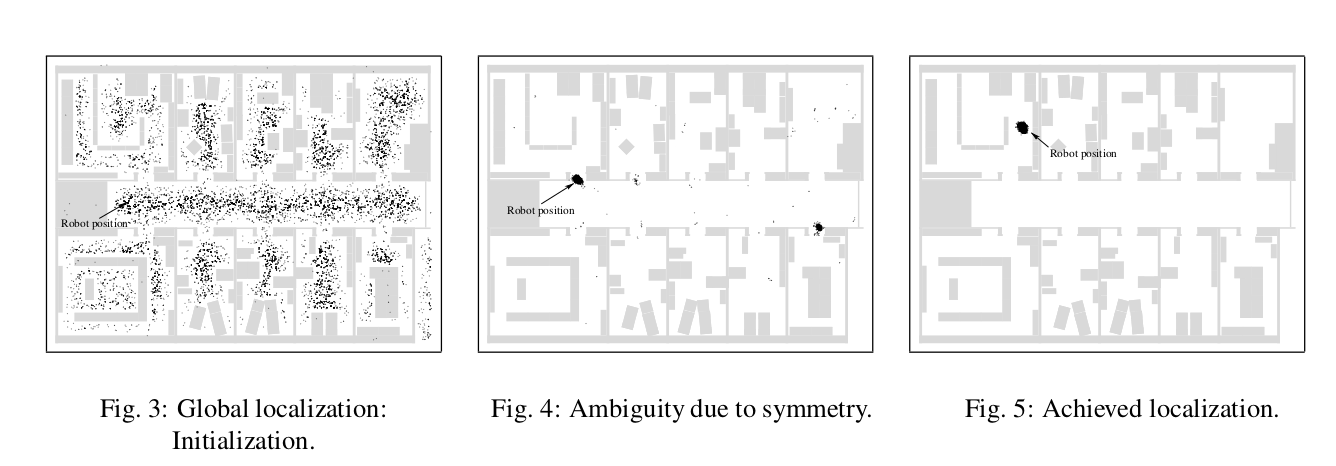
대충 개념은 알고 넘어가자. 이 이후 Fast-SLAM이라고 해서 파티클 필터를 좀더 빠르게 동작할 수 있도록 정리된게 있는데, 그건 다음기회에 읽어보기로 한다.
Code Review
이 개념을 FastSLAM에서 이어받아 구현했다. 그래서 이 코드는 FastSLAM 1.0을 베이스로 한다. 코드는 GPT의 도움을 매우 착실하게 받았다.
1. 데이터 구조
가장 먼저 해야 하는건 어떤 데이터를 쓰는가다. SLAM에서 사용하는 데이터를 생각해보자. 우선 지형정보가 있다. 이걸 우리는 Landmark라고 한다. 그리고 이 지형을 탐험하는 로봇의 위치값이 있다. Location이라고도 하고, Position이라고도 한다. 여기에 자세정보나 속도까지 더해서 Status 또는 Posture, Pose 라고도 한다. 이 로봇을 움직이는 Control Command가 있고, 로봇이 센서로 부터 관측한 정보인 Measurement가 있다.
import numpy as np
from dataclasses import dataclass, field
@dataclass
class Landmark:
mu: np.ndarray # shape: (2,) landmark position [x, y]
sigma: np.ndarray # shape: (2, 2) covariance
observed: bool = False
@dataclass
class Particle:
pose: np.ndarray # shape: (3,) [x, y, theta]
weight: float
landmarks: dict = field(default_factory=dict)
@dataclass
class Control:
v: float # linear velocity
w: float # angular velocity
2. Motion Model
이제 Map에서 로봇이 어떻게 움직이는가를 정의하자.
#각도를 -pi ~ pi로 변환한다. 즉 184도가 -176도가 되도록 한다.
def normalize_angle(angle):
return (angle + np.pi) % (2 * np.pi) - np.pi
def motion_model(pose, control, dt, noise_std):
x, y, theta = pose
v = control.v + np.random.randn() * noise_std[0]
w = control.w + np.random.randn() * noise_std[1]
x_new = x + v * dt * np.cos(theta)
y_new = y + v * dt * np.sin(theta)
theta_new = theta + w * dt
theta_new = normalize_angle(theta_new)
return np.array([x_new, y_new, theta_new])
3. Particle의 초기화
Particle filter 알고리즘에서 쓸 파티클들을 초기화한다.
def initialize_particles(num_particles, init_pose):
particles = []
for _ in range(num_particles):
#파티클 클래스 p를 정의한다.
#그걸 particles 리스트에 추가한다.
p = Particle(
pose=init_pose.copy(),
weight=1.0 / num_particles,
landmarks={}
)
particles.append(p)
return particles
4. Prediction
Particle들이 무엇이었는지 다시한번 떠올려보자. 그렇다. 바로 로봇의 위치다. 사용자 Command에 의해 로봇이 움직였다면 그것에 따라 파티클들을 움직여야 한다.
def predict_particles(particles, control, dt, motion_noise):
# 파티클들을 control 입력에 따라 이동시킨다.
for p in particles:
p.pose = motion_model(
pose=p.pose,
control=control,
dt=dt,
noise_std=motion_noise
)
5. Observation Model
#z = [range, bearing, landmark_id]
def observation_model(pose, landmark_mu):
x, y, theta = pose
mx, my = landmark_mu
dx = mx - x
dy = my - y
r = np.sqrt(dx**2 + dy**2)
bearing = np.arctan2(dy, dx) - theta
bearing = normalize_angle(bearing)
return np.array([r, bearing])
6. Landmark 초기화
랜드마크 관측값을 초기화한다. 각각의 파티클들을 기준으로, 랜드마크의 위치를 계산에서 파티클값에 저장한다. 즉, GT(Ground Truth)값이다
#r, bearing, landmark_id
def initialize_landmark(particle, measurement, measurement_noise):
r, bearing, landmark_id = measurement
x, y, theta = particle.pose
mx = x + r * np.cos(theta + bearing)
my = y + r * np.sin(theta + bearing)
mu = np.array([mx, my])
sigma = np.eye(2) * 1.0
particle.landmarks[int(landmark_id)] = Landmark(
mu=mu,
sigma=sigma,
observed=True
)
7. 실제 관측 업데이트
각 particle이 현재 관측값을 보고 자기 map을 업데이트하고, 관측과 얼마나 잘 맞는지 평가하여 weight를 수정한다
def update_particles_with_observations(particles, measurements, measurement_noise):
for p in particles: #파티클 전체 순회
for z in measurements: #파티클에서 관측한 값 전체 순회
r, bearing, landmark_id = z #관측값을 받아오고,
landmark_id = int(landmark_id)
if landmark_id not in p.landmarks:
initialize_landmark(p, z, measurement_noise) #처음 본 랜드마크 id면 초기화하고,
else:
update_landmark_ekf(p, z, measurement_noise) #이미 본 적 있는 랜드마크면 칼만필터를 통해 업데이트한다.
8. Jacobian 계산
Observation Model을 landmark 위치 주변에서 선형화(linearization)하기 위한 함수
sqrt, atan2 같은 함수를 사용하기때문에, 비선형시스템이 되어버린다. 따라서 Jacobian을 이용하여 선형근사한다.
EKF 연산에 필요하다.
def compute_jacobian(pose, landmark_mu):
x, y, theta = pose
mx, my = landmark_mu
dx = mx - x
dy = my - y
q = dx**2 + dy**2
sqrt_q = np.sqrt(q)
H = np.array([
[dx / sqrt_q, dy / sqrt_q],
[-dy / q, dx / q]
])
return H
9. Measurement likelihood 계산
def measurement_likelihood(innovation, S):
dim = len(innovation)
det_S = np.linalg.det(S)
inv_S = np.linalg.inv(S)
norm_const = 1.0 / np.sqrt((2 * np.pi) ** dim * det_S)
exponent = -0.5 * innovation.T @ inv_S @ innovation
return norm_const * np.exp(exponent)
10. Landmark EKF Update
def update_landmark_ekf(particle, measurement, measurement_noise):
r, bearing, landmark_id = measurement
landmark_id = int(landmark_id)
landmark = particle.landmarks[landmark_id]
z = np.array([r, bearing])
z_hat = observation_model(particle.pose, landmark.mu)
innovation = z - z_hat
innovation[1] = normalize_angle(innovation[1])
H = compute_jacobian(particle.pose, landmark.mu)
R = measurement_noise
S = H @ landmark.sigma @ H.T + R
K = landmark.sigma @ H.T @ np.linalg.inv(S)
landmark.mu = landmark.mu + K @ innovation
I = np.eye(2)
landmark.sigma = (I - K @ H) @ landmark.sigma
likelihood = measurement_likelihood(innovation, S)
particle.weight *= likelihood
11. Weight Normalize
def normalize_weights(particles):
total_weight = sum(p.weight for p in particles)
if total_weight == 0:
n = len(particles)
for p in particles:
p.weight = 1.0 / n
return
for p in particles:
p.weight /= total_weight
12. Resampling
확율이 떨어지는 파티클들을 제거하고, 새로운 파티클을 샘플링하는 과정이다.
def resample_particles(particles):
n = len(particles)
weights = np.array([p.weight for p in particles])
indices = np.random.choice(
np.arange(n),
size=n,
replace=True,
p=weights
)
new_particles = []
for idx in indices:
old_p = particles[idx]
new_p = Particle(
pose=old_p.pose.copy(),
weight=1.0 / n,
landmarks={
lm_id: Landmark(
mu=lm.mu.copy(),
sigma=lm.sigma.copy(),
observed=lm.observed
)
for lm_id, lm in old_p.landmarks.items()
}
)
new_particles.append(new_p)
return new_particles
13. Main,전체 Flow
지금까지의 Flow과정을 정리하면 다음과 같다.
- 파티클들의 pose를 control command를 이용해 예측하고,
- 파티클들의 관측값을 업데이트한 다음
- 확율이 높은 샘플은 남기고, 낮은 샘플들은 버리는 과정을 반복한다.
def fastslam_step(
particles,
control,
measurements,
dt,
motion_noise,
measurement_noise
):
# 1. Prediction
predict_particles(particles, control, dt, motion_noise)
# 2. Landmark update + weight update
update_particles_with_observations(
particles,
measurements,
measurement_noise
)
# 3. Normalize
normalize_weights(particles)
# 4. Resampling
particles = resample_particles(particles)
return particles
실습 코드의 실행
아래 링크를 눌러 모두 실행해보면 제일 마지막에 애니메이션 된 결과를 볼 수 있다. Open in Colab
오늘 요약
화이팅.
댓글남기기