
Term Project. Classification
학교 수업 복습 칸입니다. 26년 Machine-Learning
- 코너스톤
- 기말과제
들어가면서.
요샌 GPT가 참 똑똑해서. 한방에 끝나버렸다. 그래도 이해는 해야 하니까, Reverse way로 이해해보고자 한다.
Intro
데이터셋이 주어졌을때, 이것을 분류하는 문제는 오래된 문제였다. 어떤 교재를 보던 흔하게 묻는 질문, 개/고양이를 구분하는 방법이 바로 그것이다.
그걸 위해서 선형회귀를 쓰기도 하고, KNN Clustering을 하기도 한다. ImageNet Challenge대회를 시작으로, 어느순간 다 풀린듯 하지만, 아직도 해야 할 부분이 많은 분야의 학문이기도 하다.
이제 이미지를 구분하기 위해서 본격적으로 Feature라는 개념을 가져와보기로 한다. 이미지의 숫자가 많아지고, 분류해야 할 카테고리가 많아지며, 서로간의 유사성을 선형적으로 구분하기 힘들어짐에 따라 이미지들의 공간을 Feature라는 표현방식으로 바꾸고 이것을 구분하고자 한다.
이거 어디서 많이 본 것 아닌가? 일종의 kernel을 이용한다고 보면 쉬우려나? 다양한 특성들을 분리하기 좋은 공간으로 매핑하는 연산이라고 생각하면 커널의 특성을 가지고 있다고 봐도 될듯 싶다. 실제로 CNN의 각 필터는 커널이며, Auto Encoder의 경우 Encoder에 CNN이 들어가므로, 커널의 특성을 십분 활용한다고 해도 과언이 아닐 것이다.
이때 사용할수 있는 Feature representation, 즉 Feature로 변환하는 방법에는 CNN, AutoEncoder, PCA 등이 있고, 이 세가지 모두 실습을 통해 경험해본 바 있다. 여기서 좀 더 해볼만한건 Transformer정도 있을까?
이것도 나중에 한번 해볼 법 하겠다.
# Method
이번 실습 / 프로젝트에서는 다음과 같은 설정으로 진행된다.
- 데이터셋: KMNIST, CIFAR-10
- 특징 표현: PCA, AutoEncoder latent, CNN embedding
- 군집 방법: K-means, Gaussian Mixture Model
- 평가: ARI, NMI, Purity, Hungarian clustering accuracy, Silhouette
데이터셋
### 1. KMNIST
KMNIST(Kuzushiji-MNIST)는 일본 국립정보학연구소(NII)와 ROIS-DS Center for Open Data in the Humanities 가 공개한 데이터셋으로, 고전 일본어 문자인 쿠즈시지(Kuzushiji) 를 인식하기 위한 벤치마크 데이터셋이라 한다. https://codh.rois.ac.jp/kmnist/index.html.en
기본적으로 MNIST (0~9 숫자) -> KMNIST (일본 고문서 문자)란 뜻이다. 이미지의 크기는 28 x 28이며, 흑백(1 channel)구성이다. 클래스의 숫자는 10개이며, 학습데이터는 60,000장이다. 테스트 데이터는 10,000장으로 MNIST와 숫자는 동일하다.
이미지가 작아 학습이 매우 빠르지만, 숫자와 달리 필체 변화가 커서 어렵다.
| Label | 현대 문자 |
|---|---|
| 0 | お |
| 1 | き |
| 2 | す |
| 3 | つ |
| 4 | な |
| 5 | は |
| 6 | ま |
| 7 | や |
| 8 | れ |
| 9 | を |

### 2. CIFAR-10 CIFAR-10은 Alex Krizhevsky, Vinod Nair, Geoffrey Hinton 이 개발한 대표적인 이미지 분류 벤치마크 데이터셋이다. https://cave.cs.toronto.edu/kriz/cifar.html
이미지 크기는 32 x 32 , RGB 컬러이미지며, 클래스 수는 10개다. 학습데이터는 50,000장이며, 테스데이터는 10,000장이다.
| Label | Class |
|---|---|
| 0 | Airplane |
| 1 | Automobile |
| 2 | Bird |
| 3 | Cat |
| 4 | Deer |
| 5 | Dog |
| 6 | Frog |
| 7 | Horse |
| 8 | Ship |
| 9 | Truck |

Feature Representation
이번 실습에서 사용해볼 Feature 변환 방법은 크게 3가지다. PCA, CNN, Auto Encoder다. 마음같아선 Transformer도 추가하고 싶지만, 일단 여유가 되면 한번 해보기로 한다.
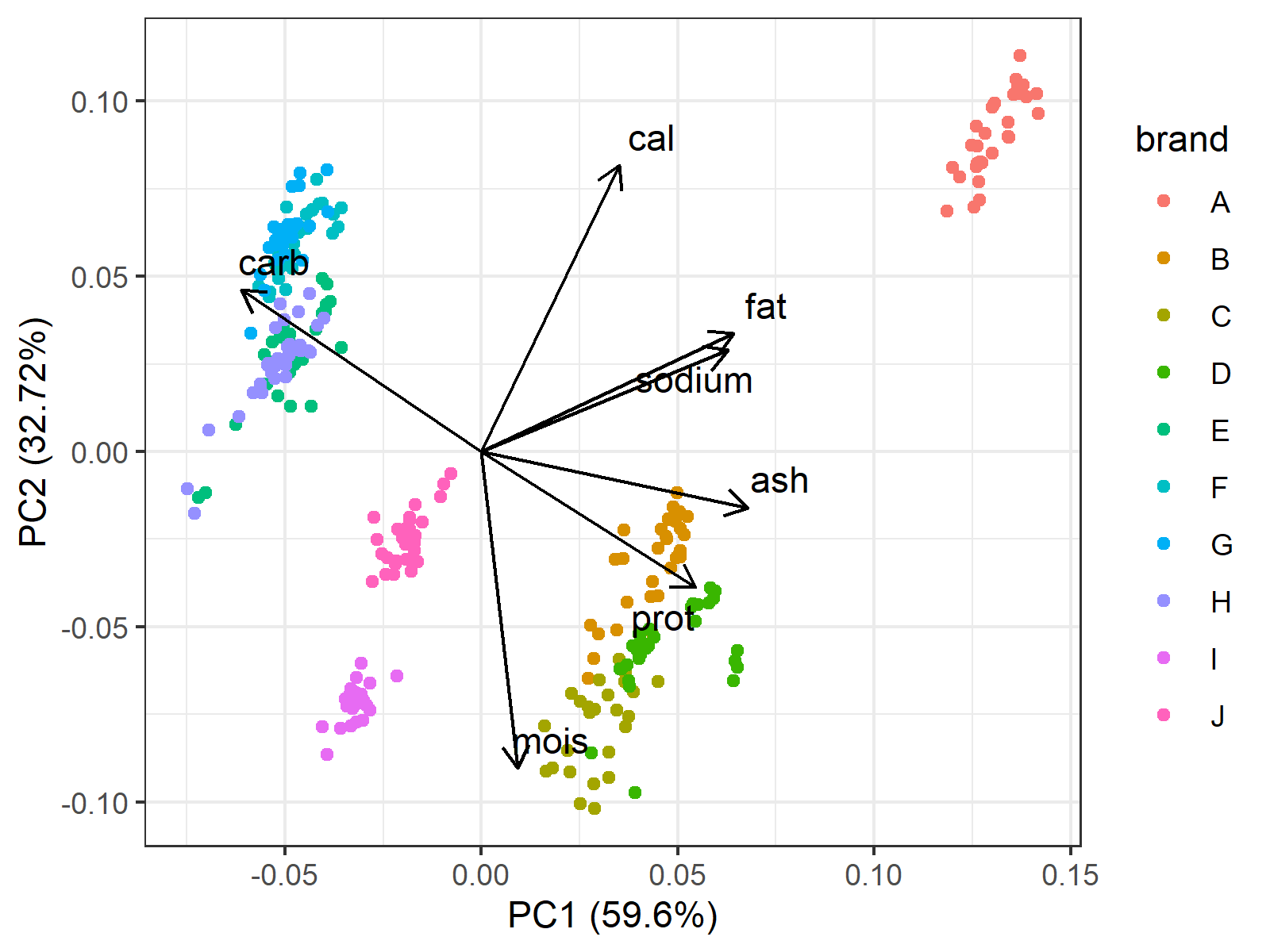
### 1. PCA (Principal Component Analysis)
이건 차원축소의 방법으로 많이 쓰이지만, 엄밀히 말해 이미지 x를 저차원벡터 z로 변환시키는 방법이기도 하다. 따라서, CNN과 Auto Encoder의 비교/대조군으로서 생각해보는게 좋을듯 싶다. 즉 이게 잘 되면 굳이 CNN까지 써야 하는가 하는 고민도 해봐야 한다는 뜻이다.
데이터 $X$ 가 있을때,
이 데이터의 공분산행렬은 \(\Sigma = \frac{1}{N} X^TX\) 로 표현할 수 있으며, 이를 고유값분해를 통해 주성분을 분석할 수 있다.
\[\Sigma v_i = \lambda_i v_i\]- $v_i$ : 주성분 방향
- $\lambda_i$ : 해당방향의 분산
따라서 가장 큰 방향 두어가지만 남기고 차원을 축소시키는 방식으로 많이 사용한다.
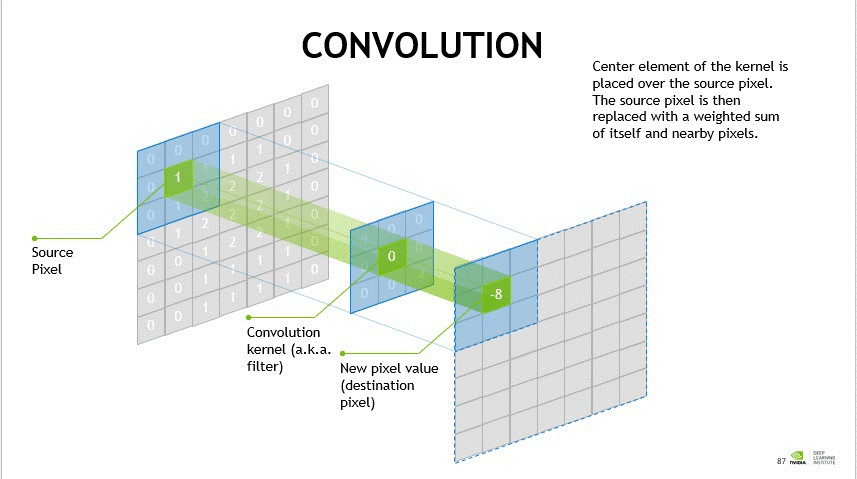
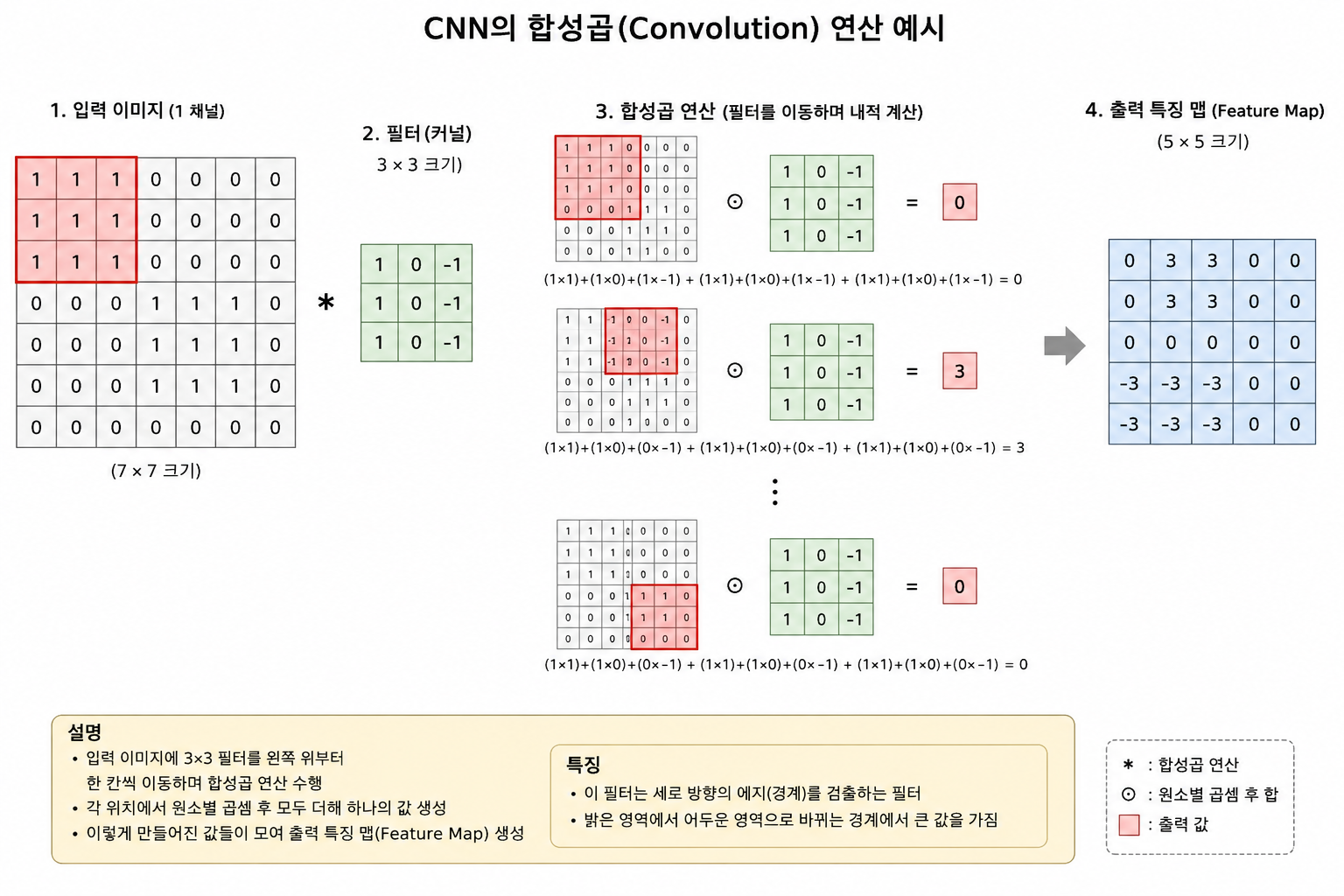
### 2. CNN
CNN은 이미지의 중요한 특징(Feature)을 자동으로 찾아서 분류하는 신경망을 말한다.
이 부분은 널리 알려져있으니, 코드 분석에서 다시금 다루기로 한다.
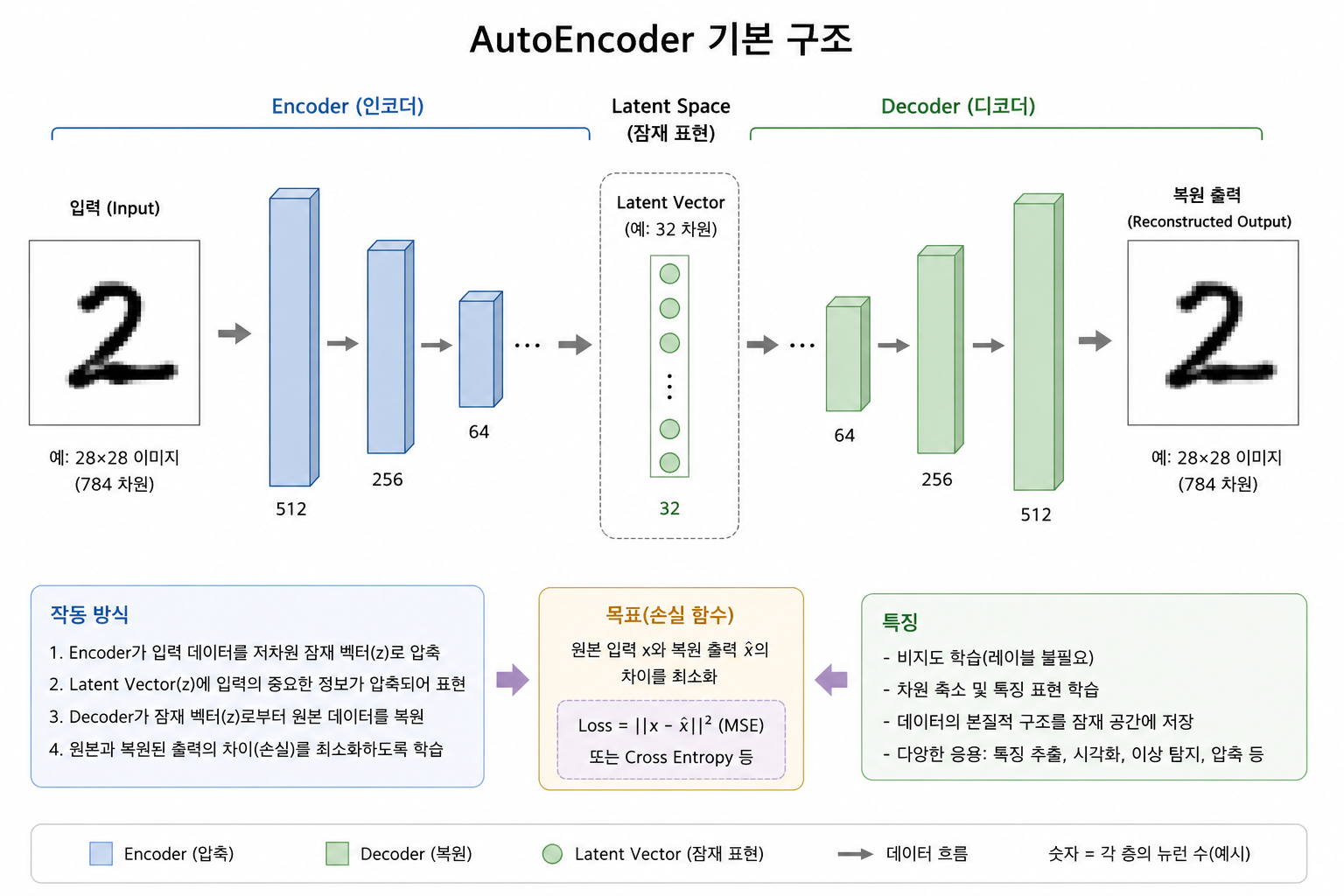
### 3. Auto Encoder
한줄 요약해본다면, 입력을 압축했다가 다시 복원하도록 학습하면서 중요한 특징(Feature)을 스스로 찾아내는 신경망이라 말할 수 있다. 요새는 챗GPT에게 설명을 부탁하면서 그림을 그려달라고 하면 잘 그려준다. 이 부분도 이후 코드에서 상세히 알아보도록 한다.
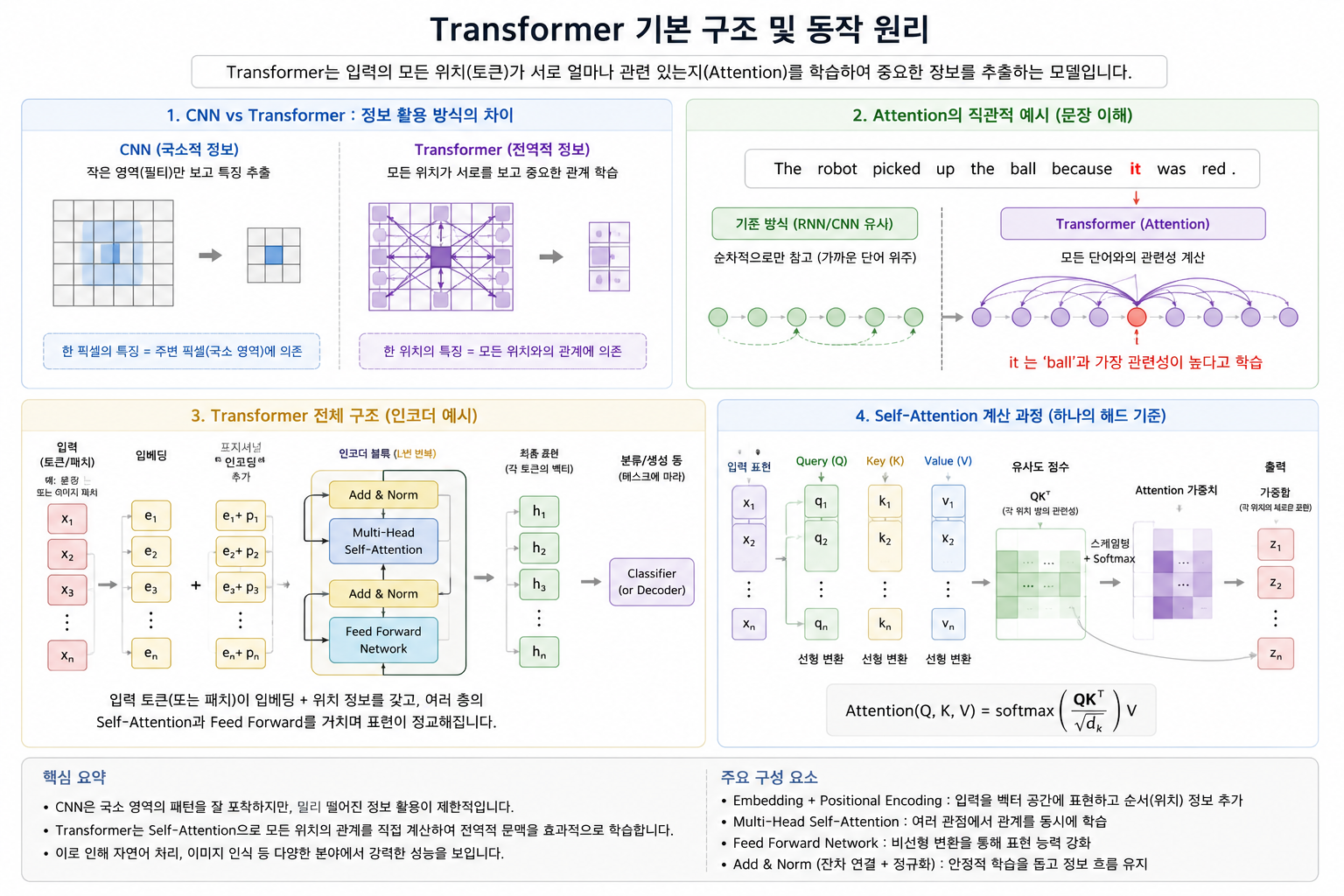
### 4. (option) Transformer
데이터의 각 부분이 서로 얼마나 관련 있는지를 학습하여 중요한 정보를 추출하는 모델이다. 이 분야를 알기 위해선 Attention에 대해서 이해해야 한다. 다만 간단히 CNN과 비교해 설명해본다면, CNN은 주변을 보며 특징을 찾는 모델이고, Transformer는 전체를 보며 관계를 찾는 모델이라 할 수 있다.
Clustering
이미지들을 분류하기 위해 Feature로 변환했다면, 진정한 분류를 위해 이제 비슷한 Feature들끼리 묶는 작업을 해야 한다. 그것을 한국어로 군집화, 영어로 Clustering이라고 한다. 이것도 일종의 머신러닝이어서, 큰 카테고리에서는 비지도학습으로 분류한다.
이번 과제에서는 K-means, Gaussian Mixture Model 두가지가 Clustering에 사용된다. 만약 여유가 있다면 DBSCAN정도는 한번 써봄직할듯하다.
### K-means 데이터를 K개의 그룹으로 나누고, 각 데이터가 가장 가까운 그룹 중심(Centroid)에 속하도록 반복적으로 군집을 형성하는 알고리즘이다. Hard Clustering이라고 말하기도 하는데, 이는 하나의 데이터가 하나의 클러스터에 배정되는 특성을 말한다.
### Gaussian Mixture Model
데이터가 여러 개의 가우시안(정규분포)이 섞여서 생성되었다고 가정하고, 각 데이터가 어느 분포에 속할 확률을 추정하는 클러스터링 기법. K-Means의 경우 하나의 데이터가 하나의 클러스터에 속한다면, GMM에선 클러스터에 속할 확율로 나타내므로, 두개 혹은 세개의 클러스터에 배정될 수도 있다. 따라서 Soft Clustering이라고 표현한다. 보통 EM알고리즘을 통해 구한다.
\[P(x) = \sum_{k=1}^{K} \pi_k \mathcal{N}(x|\mu_k,\Sigma_k)\]- K : Gaussian 개수
- $\pi_k$ : Mixing coefficient
- $\mu_k $ : 평균
- $\Sigma_k$ : 공분산
코드
# N_CLUSTERS 는 클래스의 개수만큼 정한다.
from sklearn.mixture import GaussianMixture
GMM_COVARIANCE_TYPE = "tied" #["diag", "full", "tied", "spherical"] 중 하나를 쓴다.
GMM_REG_COVAR = 1e-6 #0이 아닐것.
gmm = GaussianMixture(
n_components=N_CLUSTERS,
covariance_type=GMM_COVARIANCE_TYPE,
reg_covar=GMM_REG_COVAR,
random_state=SEED,
)
labels_gmm_pca = gmm.fit_predict(X_train_pca)
Validation
ARI, NMI, Purity, Hungarian clustering accuracy, Silhouette
### ARI (Adjusted Rand Index) 출처 : L. Hubert and P. Arabie (1985) Comparing Partitions, Journal of the Classification, 2, pp. 193-218.
클러스터링 결과와 실제 라벨의 일치도를 측정하는 지표,
같은 클래스인 데이터들이 같은 클러스터에 모였는가?
값은 -1~1사이이며, 클러스터 번호 영향을 받지 않고, 우연히 맞은 경우를 보정해준다.
수식으로 본다면 다음과 같다.
\[ARI = \frac{ RI - E[RI] }{ \max(RI) - E[RI] }\]E 는 기대값(평균)이고. 그러면 RI는 무엇인가? 헸을때,
\[RI = \frac{ TP + TN }{ TP + FP + FN + TN }\] 1 : 완벽
0 : 랜덤 수준
<0 : 랜덤보다 나쁨
코드에서의 사용
from sklearn.metrics import adjusted_rand_score
adjusted_rand_score(y_true, cluster_labels)
NMI (Normalized Mutual Information)
Strehl, A., & Ghosh, J. (2002). Cluster Ensembles: A Knowledge Reuse Framework for Combining Multiple Partitions. Journal of Machine Learning Research.
정보이론에 기반하며, 클러스터와 실제 라벨이 공유하는 정보량을 측정한다.
값의 범위는 0~1이며, 1은 완벽함을 뜻한다. 클러스터 수가 달라도 비교 가능하여, 많이 사용한다.
클러스터를 알면 실제 라벨을 얼마나 예측할 수 있는가?
이때 Mutual Informaition은 다음과 같으며, \(I(U;V) = \sum_{i,j} P(i,j) \log \frac{ P(i,j) }{ P(i)P(j) }\)
Entropy는 다음과 같다.
\[H(V) = -\sum_j P(j)\log P(j)\]코드
코드 안에서는 다음과 같이 사용된다.
from sklearn.metrics import normalized_mutual_info_score
normalized_mutual_info_score(y_true, cluster_labels)
### Purity Manning, Raghavan, Schütze. Introduction to Information Retrieval (2008)
각 클러스터 안에서 가장 많은 클래스의 비율
- $N$ : total number of samples
- $K$ : number of clusters
- $C_k$ : set of samples assigned to cluster $k$
- $T_j$ : set of samples whose true class is $j$
-
$ C_k \cap T_j $ : number of samples in cluster $k$ that belong to true class $j$
위의 수식을 바탕으로 예시를 들어보자. 실제 정답(Label)을 다음과 같이 가정하자.
고양이 5
개 5
클러스터를 2개로 설정하고 클러스터링을 진행해서 다음과같이 분류되었다고 가정하자.
Cluster 1 : 고양이 4, 개 1
Cluster 2 : 고양이 1, 개 4
| 이제, Cluster 1 ($C_1$)대해서 $max_j | C_1 \cap T_j | = 4$가 된다. (고양이가 제일 많으니까.) |
| 반대로 Cluster 2 ($C_2$)는? 마찬가지로 $max_j | C_2 \cap T_j | = 4$가 된다. (여긴 개가 제일 많으니까.) |
전체 데이터 수 N은 10이고, 좀전의 Max 값의 합산 즉, $\Sigma$를 계산하면 4+4=8이므로. Purity는 0.8이 된다.
즉 클러스터들의 순도를 나타내는 것인데.. 문제는 클러스터마다 1개의 데이터만 들어가게 되는 경우 Purity가 1이 되면서 의미 없는 데이터가 될 수도 있다. 그래서 보조지표로 많이 사용한다.
코드
def clustering_purity(y_true, cluster_labels, n_classes=10):
correct = 0
for cluster_id in np.unique(cluster_labels):
mask = (cluster_labels == cluster_id)
counts = np.bincount(y_true[mask], minlength=n_classes)
correct += np.max(counts)
purity = correct / len(y_true)
return purity
clustering_purity(y_true,cluster_labels)
### Hungarian Clustering Accuracy (또는 Clustering Accuracy)
Kuhn, H. W. (1955). The Hungarian Method for the Assignment Problem.
클러스터 번호와 실제 라벨을 최적으로 매칭한 뒤 계산하는 Accuracy
Hungarian 알고리즘을 이용해서 각각의 인스턴스들을 클러스터에 배치했을때, 인스턴스들과 클러스터들간의 구분이 잘 되었는가를 표현한다. 예를 들어,
고양이, 개, 말
이 있다고 가정해보자. 클러스터 결과
2,0,1
이 나오면, 고양이는 2, 개는 0, 말은 1이라는 클러스터에 배정되는 것이다.
따라서
\[Accuracy = \frac{Correct}{total}\]의 수식에 따라 1.0이 나온다. 만약 데이터의 숫자가 많아져서, 0.95가 나온다면 95%정확도를 뜻하므로 직관적이다는 장점이 있다
### Silhouette Score
앞선 방법들(ARI, NMI, ACC)는 정답 라벨이 필요했지만,
이 실루엣은 정답라벨이 필요가 없다.
클러스터 내부는 얼마나 뭉쳐 있고, 다른 클러스터와는 얼마나 떨어져 있는가
수식은 다음과 같다. \(s= \frac{b-a}{max(a,b)}\) 여기서
- a: 같은 클러스터 거리
- b: 다른 클러스터 거리
이때 값은 -1(잘못 클러스터링됨) ~ 1(매우 좋음) 사이 값을 가지는데, 0.5 이상만 되어도 좋다고 이야기하며, 0이면 애매하다고 한다.
#### 코드에서
from sklearn.metrics import silhouette_score
def safe_silhouette_score(Z, labels, max_points=2000):
# Silhouette is computationally expensive, so use only a subset.
unique_labels = np.unique(labels)
if len(unique_labels) < 2:
return np.nan
if len(Z) > max_points:
rng = np.random.default_rng(SEED)
idx = rng.choice(len(Z), size=max_points, replace=False)
Z_eval, labels_eval = Z[idx], labels[idx]
else:
Z_eval, labels_eval = Z, labels
if len(np.unique(labels_eval)) < 2:
return np.nan
return silhouette_score(Z_eval, labels_eval)
safe_silhouette_score(Z, cluster_labels),
| 지표 | 의미 |
|---|---|
| ARI | 실제 라벨과 클러스터 일치도 |
| NMI | 클러스터와 라벨의 정보 공유 정도 |
| Purity | 클러스터 내부 순도 |
| Hungarian ACC | 최적 매칭 후 분류 정확도 |
| Silhouette | 클러스터가 얼마나 잘 분리되었는가 |
(Option) Linear Probe Accuracy
Linear Probe Accuracy는 최근 Representation Learning 분야에서 매우 중요하게 사용하는 평가 지표라고 한다. CLiP에서 쓴다고 하는데, 아직 원본논문을 못봐서 뭐라 말을 못하겠다.
추출된 Feature만 가지고 아주 단순한 분류기를 학습했을 때 얼마나 잘 분류되는가를 측정하는 지표
예를 들어 CNN, AutoEncoder, Transformer가 각각 Feature를 만들었다고 하자. 이때 Feature가 얼마나 좋고 나쁜지를 눈으로 보기 어려우니 Logistic Regression을 붙여 성능을 측정하는 것이다.
이를 통해, 이게 좋은 Feature에 의해서 MLP성능이 좋은 것인지, 아니면 좋은 Classifier덕분인지를 판가름할 수 있다. 만약 좋은 Feature를 뽑아냈다면, 단순 분류만으로도 충분히 성능이 나와야 한다는게 핵심 아이디어다. 그래서 Feature Representation의 질을 평가할 수 있다.
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
#Feature 추출부분은 생략했다. 어떤 모델을 사용하건, Feature 들을 추출한 텐서만 받아오면 된다.
#Feature를 이제 회귀분석해보자.
def linear_probe_accuracy(train_features,train_labels,test_features,test_labels):
clf = LogisticRegression( max_iter=5000, multi_class='multinomial')
clf.fit(train_features, train_labels)
pred = clf.predict(test_features)
acc = accuracy_score(test_labels, pred)
return acc
#아래는 실행예제
train_feat, train_label = extract_features(
encoder,
train_loader,
device
)
test_feat, test_label = extract_features(
encoder,
test_loader,
device
)
acc = linear_probe_accuracy(
train_feat,
train_label,
test_feat,
test_label
)
Experiment
실험은 다음과 같은 순서로 진행된다.
- Preparation
- Dataset
- Feature Representation / Model / Feature Extraction
- Clustering / Evaluation
- Visualization
댓글남기기